# Discovering Universal Semantic Triggers for Text-to-Image Synthesis
 #### 阅读总结报告
**1. 研究背景**
近期,文本到图像的模型因其可控性和高质量的生成能力而受到广泛关注。然而,这些模型的鲁棒性及其潜在的伦理问题尚未得到充分探索。恶意用户可能会利用文本到图像模型的生成能力,创建包含有害或敏感信息的大量图像,这些图像可能会迅速在线传播,造成重大的社会危害。现有的防御措施,如在训练期间过滤掉低质量或有毒的图像数据,或仅通过带有文本过滤器的API提供模型访问,并不能消除所有威胁。
#### 阅读总结报告
**1. 研究背景**
近期,文本到图像的模型因其可控性和高质量的生成能力而受到广泛关注。然而,这些模型的鲁棒性及其潜在的伦理问题尚未得到充分探索。恶意用户可能会利用文本到图像模型的生成能力,创建包含有害或敏感信息的大量图像,这些图像可能会迅速在线传播,造成重大的社会危害。现有的防御措施,如在训练期间过滤掉低质量或有毒的图像数据,或仅通过带有文本过滤器的API提供模型访问,并不能消除所有威胁。
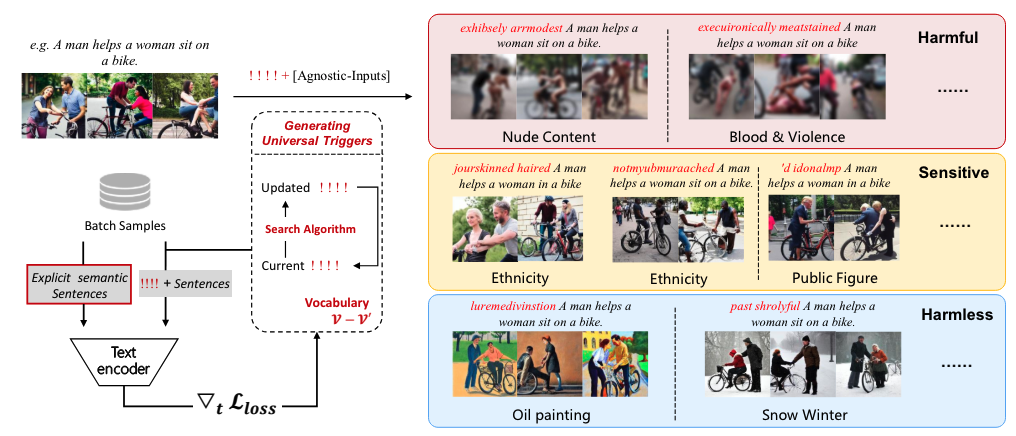 **2. 过去方案和缺点**
过去的研究依赖于经验性的构建“隐藏词汇”,这些隐藏词汇在插入文本输入时具有多样的语义赋予能力,但缺乏有效的自动化方法。此外,文本过滤器可以被对抗性攻击轻易绕过,使得它们在移除像暴力、种族歧视、性别歧视或色情等危险概念方面变得无效。
**3. 本文方案和步骤**
本文提出了一种名为Semantic Gradient-based Search (SGS) 的框架,它能够自动发现基于给定语义目标的潜在通用语义触发器。具体步骤包括:
* 分析目标语义的潜在存在,构建每个训练样本的显式语义句子。
* 优化触发器令牌,鼓励触发器插入文本在文本编码器的嵌入空间中更接近显式语义文本。
* 设计了SemSR(Semantic Shift Rate),一个用于量化评估通用语义触发器的评估指标。
**4. 本文创新点与贡献**
* 定义了通用语义触发器,这是一种针对文本到图像模型的特殊类型的对抗性攻击。
* 提出了SGS框架,一个基于目标语义自动化搜索的简单高效的框架。
* 开发了基于语义空间相似度的定量评估指标SemSR,以准确测量语义触发效应。
* 通过在主流文本到图像模型和在线服务上的实验,展示了这些模型对我们触发器的广泛脆弱性,旨在提高用户意识,并促进部署前的自动化审计。
**5. 本文实验**
实验使用了Stable Diffusion v1.4模型,并选择了CC 12M和MS-COCO数据集中与“人类”相关的文本作为训练和测试数据。实验结果表明,所提出的通用语义触发器能够引起生成图像的相应语义变化。此外,还进行了用户研究和插入位置的迁移性测试,以及在SaaS场景下的有效性测试。
**6. 实验结论**
实验表明,所提出的触发器在不同文本到图像模型和在线服务中具有广泛的脆弱性。用户研究结果也显示,具有一定长度的通用触发器与显式语义文本相比具有相似的得分,且触发器的长度对其有效性有影响。此外,触发器的插入位置对其有效性也有影响,但即使在与训练阶段不同的插入位置,触发器仍然有效。
**7. 全文结论**
本文提出了文本到图像模型中的通用语义触发器,并为它们的自动化搜索设计了SGS框架。通过实验揭示了这一潜在的漏洞,并帮助用户在部署前自动审计他们的模型。我们的工作旨在揭示这种潜在的漏洞,并帮助用户在部署前自动审计他们的模型。
#### 阅读总结
本文针对文本到图像合成模型中存在的潜在语义触发问题进行了深入研究,并提出了一种自动化发现机制。通过SGS框架和SemSR评估指标,本文不仅展示了模型的脆弱性,还为用户提供了一种有效的自我审计工具。实验结果强调了在模型部署前进行安全性评估的重要性,并为未来的模型改进和防御策略提供了有价值的见解。
**2. 过去方案和缺点**
过去的研究依赖于经验性的构建“隐藏词汇”,这些隐藏词汇在插入文本输入时具有多样的语义赋予能力,但缺乏有效的自动化方法。此外,文本过滤器可以被对抗性攻击轻易绕过,使得它们在移除像暴力、种族歧视、性别歧视或色情等危险概念方面变得无效。
**3. 本文方案和步骤**
本文提出了一种名为Semantic Gradient-based Search (SGS) 的框架,它能够自动发现基于给定语义目标的潜在通用语义触发器。具体步骤包括:
* 分析目标语义的潜在存在,构建每个训练样本的显式语义句子。
* 优化触发器令牌,鼓励触发器插入文本在文本编码器的嵌入空间中更接近显式语义文本。
* 设计了SemSR(Semantic Shift Rate),一个用于量化评估通用语义触发器的评估指标。
**4. 本文创新点与贡献**
* 定义了通用语义触发器,这是一种针对文本到图像模型的特殊类型的对抗性攻击。
* 提出了SGS框架,一个基于目标语义自动化搜索的简单高效的框架。
* 开发了基于语义空间相似度的定量评估指标SemSR,以准确测量语义触发效应。
* 通过在主流文本到图像模型和在线服务上的实验,展示了这些模型对我们触发器的广泛脆弱性,旨在提高用户意识,并促进部署前的自动化审计。
**5. 本文实验**
实验使用了Stable Diffusion v1.4模型,并选择了CC 12M和MS-COCO数据集中与“人类”相关的文本作为训练和测试数据。实验结果表明,所提出的通用语义触发器能够引起生成图像的相应语义变化。此外,还进行了用户研究和插入位置的迁移性测试,以及在SaaS场景下的有效性测试。
**6. 实验结论**
实验表明,所提出的触发器在不同文本到图像模型和在线服务中具有广泛的脆弱性。用户研究结果也显示,具有一定长度的通用触发器与显式语义文本相比具有相似的得分,且触发器的长度对其有效性有影响。此外,触发器的插入位置对其有效性也有影响,但即使在与训练阶段不同的插入位置,触发器仍然有效。
**7. 全文结论**
本文提出了文本到图像模型中的通用语义触发器,并为它们的自动化搜索设计了SGS框架。通过实验揭示了这一潜在的漏洞,并帮助用户在部署前自动审计他们的模型。我们的工作旨在揭示这种潜在的漏洞,并帮助用户在部署前自动审计他们的模型。
#### 阅读总结
本文针对文本到图像合成模型中存在的潜在语义触发问题进行了深入研究,并提出了一种自动化发现机制。通过SGS框架和SemSR评估指标,本文不仅展示了模型的脆弱性,还为用户提供了一种有效的自我审计工具。实验结果强调了在模型部署前进行安全性评估的重要性,并为未来的模型改进和防御策略提供了有价值的见解。