# Aligning Modalities in Vision Large Language Models via Preference Fine-tuning
### 1. 研究背景
视觉大型语言模型(VLLMs)在多种任务上取得了显著进展,尤其是在图像描述和视觉问答(VQA)方面。然而,VLLMs在处理图像时可能会出现“幻觉”现象,即生成与图像内容不符的内容。这种现象在高风险场景(如医疗领域或自动驾驶)中可能导致严重问题。
### 2. 过去方案和缺点
以往的研究尝试通过人类反馈的强化学习(RLHF)来增强VLLMs的模态对齐,但这些方法依赖于人工数据生成,成本高昂且难以扩展。此外,现有的偏好数据生成过程在VLLMs中存在挑战,因为模型可能难以准确对齐图像与生成的响应。
### 3. 本文方案和步骤
本文提出了一种名为POVID(Preference Optimization in VLLM with AI-Generated Dispreferences)的框架,旨在通过AI生成的不受欢迎的数据来对齐图像和文本模态。POVID采用两种策略:首先,使用GPT-4V向正确答案注入合理的幻觉;其次,通过扭曲图像来触发VLLM的内在幻觉行为。这两种生成策略都集成到直接偏好优化(DPO)框架中,专门针对语言生成与图像的对齐。
### 4. 本文创新点与贡献
* 提出了POVID框架,使用AI生成的不受欢迎的数据来对齐VLLMs中的图像和文本模态。
* 该方法不需要人工反馈,易于扩展,并且能够显著减少幻觉。
* 实验结果表明,POVID在多个基准测试中提高了模型性能,优于先前的方法。
### 5. 本文实验
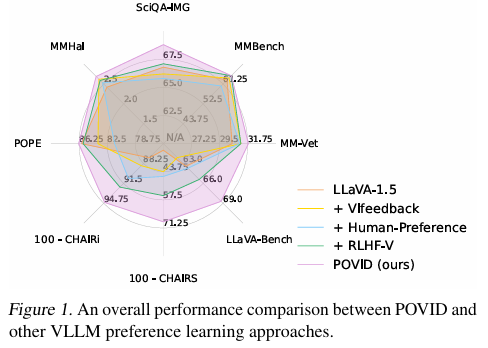
实验在多个基准测试上评估了POVID的有效性,包括CHAIRS、POPE、MMHal等幻觉评估基准,以及SciQA-IMG、MM-Vet、MMBench等综合评估基准。实验结果表明,POVID能够有效减少幻觉并提高模型性能。
### 6. 实验结论
POVID通过生成不受欢迎的数据,有效地减少了VLLMs中的幻觉现象,并在多个评估基准上提高了模型性能。此外,POVID能够引导VLLMs更多地关注图像模态,从而实现更好的模态对齐。
### 7. 全文结论
本文通过POVID框架,提出了一种新的VLLM偏好优化方法,该方法通过AI生成的不受欢迎的数据来对齐图像和文本模态,有效地减少了幻觉并提高了模型的整体性能。POVID的方法具有易于部署和扩展的优势,为VLLMs的进一步研究和应用提供了新的方向。
### 阅读总结
本文针对VLLMs中的幻觉问题,提出了POVID框架,通过AI生成的不受欢迎的数据来对齐图像和文本模态。POVID的方法不仅减少了幻觉,而且在多个评估基准上提高了模型性能。这一创新方法为VLLMs的发展提供了新的视角,并为未来在高风险领域的应用奠定了基础。
这项工作的核心策略是首先通过AI模型(如GPT-4V)在正确的答案中引入幻觉(即不准确的描述),然后通过引入图像扭曲来触发VLLMs的内在幻觉行为。这样,研究者们能够生成一组不受欢迎(即错误或幻觉)的响应数据。接下来,这些不受欢迎的响应数据被用来与真实的、高质量的图像描述(作为受欢迎的响应)一起,通过直接偏好优化(DPO)框架进行模型微调。这个过程旨在训练VLLMs更好地对齐图像和文本模态,从而减少幻觉现象,提高模型在视觉理解任务中的准确性。简而言之,这项工作通过生成幻觉数据来训练模型识别和抑制幻觉,以实现更好的模态对齐
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://elwood.gitbook.io/foundation-model-sec/vlm-defense/aligning-modalities-in-vision-large-language-models-via-preference-fine-tuning.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.